SELECT
...
FROM tbla a, (SELECT * FROM tblb WHERE ROWNUM <= 10) b
이것을
SELECT
...
이것을
SELECT
...
FROM tbla a, (SELECT * FROM dual CONNECT BY LEVEL <= 10) b
출처 : http://blog.paran.com/grinbe/10035691
[마이크로소프트] 공유된 폴더에 특정 사용자만이 접근하게 하려면 - windows xp
안녕하십니까? 윈도우 기술지원부 입니다.
아래 작업을 진행합니다.
*** 공유된 폴더에 특정 사용자만이 접근하게 하려면
xp 에서는 폴더 공유시 암호를 지정하도록 제공되지 않습니다.
다만 사용자를 지정하여 지정한 사용자 만이 폴더에 접근 할 수 있도록 설정을 하실 수 있습니다.
(환경 구성)
1. 시작 - 제어판 - 사용자 계정 - guest 계정을 사용안함으로 변경
2. 시작 - 제어판 - 관리도구 - 컴퓨터 관리 - 로컬 사용자 및 그룹 - 사용자
guest 계정 더블클릭 - 계정 사용안함에 체크 - 적용 - 확인
3. 시작 - 제어판 - 관리도구 - 로컬 보안 정책 - 로컬정책 - 보안 옵션 - 네트워크 액세스: 로컬 계정에 대한 공유 및 보안 등록 정보 부분에서
일반 - 로컬 사용자를 그대로 인증 으로 선택 - 적용 - 확인
(사용자 추가)
1. 시작 - 제어판 - 사용자 계정 - 새 계정 만들기 클릭 - 원하는 임의에 몇몇 사용자를 생성합니다. (암호도 같이 생성)
(폴더 설정하는 방법)
1. 내컴퓨터 더블클릭 - 메뉴중 도구 - 폴더 옵션 - 보기탭 - 모든 사용자에게 동일한 폴더 공유 권한을 지정(권장)에 체크를 해제 합니다 .
2. 한 폴더를 공유를 합니다. (폴더에 마우스 오른쪽 버튼을 클릭 - 공유 및 보안 클릭 - 이 폴더를 공유함에 체크)
3. 사용권한 버튼 클릭
4. 추가 클릭 - 고급 버튼 클릭 - 지금 찾기 클릭 - 접근 허용하도록 원하는 사용자 선택 - 확인 버튼 클릭 - 추가한 사용자에 모든 권한 설정
5. Everyone를 제거 해주시면 선택한 사용자 만이 그룹또는 사용자 이름에 남습니다
6. 보안탭에는 everyone이 추가되도록 합니다. (everyone에 모든권한으로 설정)
네트웍 상에서 다른 pc가 접근시 사용자 이름과 암호 묻는 창이 나오면, 고객분께서 원하는 사용자 이름과 암호를 알려주시면 됩니다.
접근 허용하도록 한 사용자로 로그인시는 공유한 폴더에 접근이 가능하며, 그렇지 못한 사용자로 로그인한 사용자는 공유한 폴더에 접근하지 못하게 됩니다.
*** 네트웍 pc 접근시 암호 물어보도록 설정하려면
아래 작업은 guest 계정으로 이용하는 방법 입니다.
1. 시작 - 제어판 - 사용자 계정 - guest 계정을 사용으로 변경
2. 시작 - 제어판 - 관리도구 - 컴퓨터 관리 - 로컬 사용자 및 그룹 - 사용자
3. guest 계정 더블클릭 - 계정 사용안함에 체크 해제 - 적용 - 확인
4. guest 계정 마우스 오른쪽 버튼클릭 - 암호 설정 - 원하는 암호 설정 - 확인
(이 후부터는 시작 - 제어판 - 사용자 계정에서 암호 변경 또는 제거를 바로 설정할 수 있습니다.)
5. 네트웍 pc 접근시 암호 물어보는 창이 먼저 실행이 됨.
(xp home은 로컬 사용자 및 그룹이 없습니다.
암호 설정을 하려면 아래 작업을 이용합니다.)
1. 시작 - 실행 - cmd 입력 - 확인
2. 아래 내용 입력 후 엔터
net user guest 원하는 암호입력 (예: net user guest 12345)
3. 명령을 잘 실행 했습니다 라고 나오면 cmd 창 닫는다
4. 시작 - 제어판 - 사용자 계정 - guest 계정을 실행하면 암호변경, 암호제거가 나타납니다.
(guest 계정은 사용으로 설정하셔야 합니다.)
업무에 도움이 되시길 바랍니다.
감사합니다.
좋은 하루 보내세요!
Microsoft Technical Support
고객 기술지원센터 : 1577-9700 (#3)
http://support.microsoft.com
=========================================================================================================
윈도우 XP는 네트워크 컴퓨터 환경 관리를 목적으로 드라이브를 공유하는데, 이 공유폴더는 숨겨져 있으며 다음과 같은 방법으로 찾을 수 있습니다.
① [시작]→[실행]→'cmd' 입력→DOS 창 생성
② C:\>net share
예를 들어, 앞에서 설명한 방법으로 공유폴더를 찾아봤더니 C$, admin$, ipc$의 3개 폴더가 공유된 것으로 나타났을 때, 다음과 같은 명령을 실행하면 공유를 제거할 수 있습니다. (C$는 C 드라이브 공유, admin$와 ipc$는 관리 공유로 바이러스에 취약할 수 있으므로 제거하는 것이 좋음)
① C:\>net share c$ /delete
② C:\>net share admin$ /delete
③ C:\>net share ips$ /delete
만약 엑세스 거부로 제거되지 않는 경우 다음과 같이 registry를 편집하여 관리공유에 대한 외부 접근을 제한합니다.
① [시작]→[실행]→"regedit" 입력
ᆼHKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Lsa
ᆼValue Name : RestrictAnonymous
ᆼData Type : Reg_DWORD
ᆼValue : 1
* 기본값으로 설정된 0을 1로 변경 : 공유폴더에 대한 접근을 제한합니다.
[출처] 정보보안백문백답 (2005. 발행처:국가정보원)
=========================================================================================================
윈도우Xp는 네트워크 상에서 컴퓨터를 관리할 목적으로 드라이브를 공유하는데,
이를 관리목적의 공유폴더라 한다. 문제는 관리목적 공유폴더를 통해
대량의 웜 바이러스들이 유입될 경우, 관리목적의 공유폴더를 차단하지 않을 경우
영원히(?) 웜 바이러스를 치료하지 못하고 치료와 재감염을 반복해야 한다.
따라서, 윈도우Xp에서 공유폴더를 찾아서 삭제하는 방법을 알아보자.
1. 현재 자신의 공유폴더 상태 확인하기
- [시작] -> [실행] -> cmd 엔터 후, net share 입력
Sharename Resource Remark
--------------------------------------------------------------------------
print$ C:\WINNT\SYSTEM\SPOOL
ADMIN$ C:\WINNT Remote Admin
C$ C:\ Default Share for Internal Use
IPC$ Remote IPC
LASER LPT1 Spooled Laser printer
위 그림에서는 현재 ADMIN$, C$, print$, IPC$ 모두 4개의 폴더가 관리목적으로
공유되어 있음을 알 수 있다. (취약점 존재함)
2. 관리목적의 공유폴더를 통해 전파되는 악성코드들은 뭐가 있나?
Win32/Parite, Win32/Opasoft.worm, Win32/LovGate.worm, IRCbot 변종 등
3. 공유폴더 해제하기
3-1) 명령어 입력을 통한 해제 : [시작] -> [실행] -> cmd 엔터 후,
- net share C$ /delete 엔터 // C$ 공유해제
- net share ADMIN$ /delete 엔터 // ADMIN$ 공유해제
- net share print$ /delete 엔터 // print$ 공유해제 (잠깐! print$란? -> 클릭)
- net share IPC$ /delete 엔터 // IPC$ 공유해제
이 방법은 부팅 후 다시 기본 공유가 설정됨으로 일시적(?) 방편이다.
3-2) 레지스트리 편집을 통한 해제 : [시작] -> [실행] -> regedit 엔터 후,
- HKLM -> System -> CurrentControlSet -> Services -> LanmanServer -> Parameters 에
아래의 조건으로 값을 새로 생성 (잠깐! 레지스트리 값 추가 어떻게? -> 클릭)
키 값 : AutoShareServer (win2k Server 의 경우 AutoShareWks)
데이터 타입 : DWORD, 값 : 0(Zero)
---> [공유폴더 지금 즉시 해제하기 : 클릭]
참고 : 외부에서 내 컴퓨터의 공유폴더에 접근하지 못하도록 차단하기
- HKLM -> System -> CurrentControlSet -> Control -> LSA 에 아래 조건으로 값 생성
키 값 : RestrictAnonymous 데이터 형식 : DWORD, 값 : 1
4. 공유폴더와 감염 및 재감염 대비책 관련 문서
- '공유폴더 안 막으면 포맷해도 치료 못한다' -> 클릭
- '관리목적 공유폴더와 그 위험성, 그리고 재감염의 연속' -> 클릭
- '잘 모른다고 방치한 관리목적 공유폴더, 이렇게 당한다.' -> 클릭
Alfa (알파)
Bravo(브라보)
Charlie(찰리)
Delta(델타)
Echo(에코)
Foxtrot(폭스트롯)
Golf(골프)
Hotel(호텔)
India(인디아)
Juliet(줄리엣)
Kilo(킬로)
Lima(리마)
Mike(마이크)
November(노벰버)
Osca(오스카)
Papa(파파)
Quebec(퀘벡)
Romeo(로미오)
Sierra(시에라)
Tango(탱고)
Uniform(유니폼)
Victor(빅터)
Wiskey(위스키)
X-ray(엑스레이)
Yankee(양키)
Zulu(즐루)
출처 : http://home.postech.ac.kr/%7Edada/methodx/reg_ex.html
PHP에서 정규표현식을 지원하는 함수로는 ereg(), eregi(), ereg_replace(), eregi_replace(), split(), spliti() 등이 있다. 이 때 ereg_replace 보다 preg_replace가 훨씬 빠르다고 한다.
이 외에도 펄 형식을 지원하는 정규표현식에 관련된 함수들도 있다.
First of all, let's take a look at two special symbols: '^ (start)' and '$ (end)'.
There are also the symbols '* (zero or more)', '+ (one or more)', and '? (zero or one)', which denote the number of times a character or a sequence of characters may occur.
You can also use bounds, which come inside braces and indicate ranges in the number of occurences:
Now, to quantify a sequence of characters, put them inside parentheses:
There's also the '|' symbol, which works as an OR operator:
A period ('.') stands for any single character:
Bracket expressions specify which characters are allowed in a single position of a string:
You can also list which characters you DON'T want -- just use a '^' as the first symbol in a bracket expression (i.e., "%[^a-zA-Z]%" matches a string with a character that is not a letter between two percent signs).
\ 는 특수 문자를 문자 자체로 해석하도록 하는 Escape 문자로 사용된다. ? 자체를 찾으려고 하면 \? 와 같이 사용되어야 한다.
\ 를 사용해야 하는 문자로는 ^ \ | [] () {} . * ? + 가 있다. 이 문자들을 문자 자체로 해석을 하기위해서는
\^ \\ \| \[ \( \{ \. \* \? \+ 등과 같이 사용해야 한다.
In order to be taken literally, you must escape the characters "^.[$()|*+?{\" with a backslash ('\'), as they have special meaning.
On top of that, you must escape the backslash character itself in PHP3 strings, so, for instance, the regular expression "(\$|?[0-9]+" would have the function call: ereg("(\\$|?[0-9]+", $str) (what string does that validate?)
Just don't forget that bracket expressions are an exception to that rule--inside them, all special characters, including the backslash ('\'), lose their special powers (i.e., "[*\+?{}.]" matches exactly any of the characters inside the brackets). And, as the regex man pages tell us: "To include a literal ']' in the list, make it the first character (following a possible '^'). To include a literal '-', make it the first or last character, or the second endpoint of a range."
예를 들어 what?이라는 물음표로 끝나는 문자를 찾고 싶다고, egrep 'what?' ...이라고 하면 ?이 특수문자이므로 wha를 포함한 whale도 찾게 된다. 또, 3.14로 찾을때는 3+14 등도 찾게 된다.
특수문자가 [] 안과 밖에서 다르다는 점을 생각하여 각각의 경우를 살펴보자. 우선 [] 밖의 경우는,
첫번째 방법은 보통 escape라고 부르며, 특수문자 앞에 \을 붙여서 특수문자의 특수한 기능을 제거한다. 두번째 방법은 [] 밖의 많은 특수문자들이 [] 안에서는 일반문자가 되는 점을 이용한 것이다. 보통 첫번째 방법을 많이 사용한다.
이 때 \도 뒤에 나오는 특수문자를 일반문자로 만드는 특수문자이기 때문에, 문자 그대로의 \을 나타내려면 \\을 사용해야 한다. 물론 [\]도 가능하다.
[] 안의 특수문자는 위치를 바꿔서 처리한다. 먼저, ^는 [^abc]와 같이 처음에 나와야만 의미가 있으므로 [abc^]와 같이 다른 위치에 사용하면 된다. -는 [a-z]와 같이 두 문자 사이에서만 의미가 있으므로 [-abc]나 [abc-]와 같이 제일 처음이나 마지막에 사용한다. (grep과 같이 도구에 따라 역으로 일반 문자앞에 \를 붙여서 특수문자를 만드는 경우가 있다.)
For completeness, I should mention that there are also collating sequences, character classes, and equivalence classes. I won't be getting into details on those, as they won't be necessary for what we'll need further down this article. You should refer to the regex man pages for more information.
character class의 예
Ok, we can now use what we've learned to work on something useful: a regular expression to check user input of an amount of money. A quantity of money can be written in four ways we can consider acceptable: "10000.00" and "10,000.00", and, without the cents, "10000" and "10,000". Let's begin with:
^[1-9][0-9]*$
That validates any number that doesn't start with a 0. But that also means the string "0" doesn't pass the test. Here's a solution:
^(0|[1-9][0-9]*)$
"Just a zero OR some number that doesn't start with a zero." We may also allow a minus sign to be placed before the number:
^(0|-?[1-9][0-9]*)$
That means: "a zero OR a possible minus sign and a number that doesn't start with a zero." Ok, let's not be so strict and let the user start the number with a zero. Let's also drop the minus sign, as we won't be needing it for the money string. What we could do is specify an optional decimal fraction part in the number:
^[0-9]+(\.[0-9]+)?$
It's implicit in the highlited construct that a period always comes with at least one digit, as a whole set. So, for instance, "10." is not validated, whereas "10" and "10.2" are.
^[0-9]+(\.[0-9]{2})?$
We specified that there must be exactly two decimal places. If you think that's too harsh, you can do the following:
^[0-9]+(\.[0-9]{1,2})?$
That allows the user to write just one number after the period. Now, as for the commas separating the thousands, we can put in:
^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?$
"A set of 1 to 3 digits followed by zero or more sets of a comma and three digits." Easy enough, isn't it? But let's make the commas optional:
^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(\.[0-9]{1,2})?$
That's it. Don't forget that the '+' can be substituted by a '*' if you want empty strings to be accepted also (why?). And don't forget to escape the backslash for the function call (common mistake here). Now, once the string is validated, we strip off any commas with str_replace(",", "", $money) and typecast it to double so we can make math with it.
Ok, let's take on e-mail addresses. There are three parts in an e-mail address: the POP3 user name (everything to the left of the '@'), the '@', and the server name (the rest). The user name may contain upper or lowercase letters, digits, periods ('.'), minus signs ('-'), and underscore signs ('_'). That's also the case for the server name, except for underscore signs, which may not occur.
Now, you can't start or end a user name with a period, it doesn't seem reasonable. The same goes for the domain name. And you can't have two consecutive periods, there should be at least one other character between them. Let's see how we would write an expression to validate the user name part:
^[_a-zA-Z0-9-]+$
That doesn't allow a period yet. Let's change it:
^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*$
That says: "at least one valid character followed by zero or more sets consisting of a period and one or more valid characters."
To simplify things a bit, we can use the expression above with eregi(), instead of ereg(). Because eregi() is not sensitive to case, we don't have to specify both ranges "a-z" and "A-Z" -- one of them is enough:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*$
For the server name it's the same, but without the underscores:
^[a-z0-9-]+(\.[a-z0-9-]+)*$
Done. Now, joining both expressions around the 'at' sign, we get:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$
Microsoft .NET framework의 RegularExpressionValidate 컨트롤에서는
^[_a-zA-Z0-9]+([-+.][_a-zA-Z0-9]+)*@[_a-zA-Z0-9]+([-.][_a-zA-Z0-9]+)*\.[_a-zA-Z0-9]+([-.][_a-zA-Z0-9]+)*$
이렇게 쓰고있다. 이게 더 정확한 듯 하다. 위의 것은 '-'으로 시작하는 것을 허용하는데 이것은 그렇지 않다.
주민등록번호는 "6자리의 숫자 - (1|2|3|4)로 시작하는 7자리의 숫자" 의 형태로 되어있다.
[0-9]{6}-(1|2|3|4)[0-9]{6}
<script language="javascript">
<!--
function realCheck(Str) {
var fooPat=/^[1-9][0-9]*(\.[0-9]+)?$/
var matchArray=Str.match(fooPat)
if (matchArray==null) {return false;}
return true;
}
function positiveIntCheck(Str) {
var fooPat=/^[1-9][0-9]*$/
var matchArray=Str.match(fooPat)
if (matchArray==null) {return false;}
return true;
}
//-->
</script>
URL주소의 형식은 www.aaa.net 과 같으며 영숫자 . \ ? & _ = ~ + 등으로 이루어져 있다.
[0-9a-zA-Z_]+(\.[0-9a-zA-Z/\?_=+~]+)*
(http|ftp|https):/{2}[0-9a-zA-Z_]+(\.[0-9a-zA-Z/\?_=+~]+)*
if(!eregi("^([[:alnum:]_%+=.-]+)@([[:alnum:]_.-]+)\.([a-z]{2,3}|[0-9]{1,3})$",$email))
{
echo "잘못된 email address 다.";
}
if(!ereg("([^[:space:]])",$name)) {
echo("<script>alert('이름을 입력하세요!');history.go(-1)</script>");
exit;
}
if(!ereg("([a-zA-Z0-9]+)@([a-zA-Z0-9])([.a-zA-Z0-9]+)([a-zA-Z0-9])$",$email)) {
echo("<script>alert('올바른 E-Mail 주소가 아닙니다.');history.go(-1)</script>");
exit;
}
if(!ereg("(^[0-9a-zA-Z]{4,8}$)",$passwd)) {
echo("<script>alert('비밀번호는 4자에서 8자까지의 영문자 또는 숫자로 입력하세요!');history.go(-1)
</script>");
exit;
}
if(!ereg("([^[:space:]])",$title)) {
echo("<script>alert('제목을 입력하세요!');history.go(-1)</script>");
exit;
}
ereg() and eregi() have a feature that allows us to extract matches of patterns from strings (read the manual for details on how to use that). For instance, say we want do get the filename from a path/URL string -- this code would be all we need:
ereg("([^\\/]*)$", $pathOrUrl, $regs);
echo $regs[1];
ereg_replace() and eregi_replace() are also very useful: suppose we want to separate all words in a string by commas:
ereg_replace("[ \n\r\t]+", ",", trim($str));
정규식을 이용하여 문자열을 찾는 함수는 ereg()와 eregi() 함수이다. 이 함수 문자열에서 찾고자 하는 문자의 패턴이 있는지 확인할 수 있다. 그런데 문자열이 존재하는지 확인만하고 어떤 문자열을 찾았는지 볼수 있는 방법은 없을까?
→ ereg("a(b*)(c+)", "abbbbcccd", $reg);
다음과 같이 세번째 인자를 주면 주어진 패턴과 일치하는 문자열을 구할수 있다. 그럼 $reg 에는 어떤것들이 저장되어있을까 ? $reg는 배열의 형태로 반환이 된다.
$reg[0] 에는 주어진 전체 패턴인 a(b*)(c+)에 대한 내용이 들어간다. 위의 함수 결과에서는 abbbbccc 가 된다.
$reg[1]에는 첫 번째 (b*) 에 해당하는 bbbb가 들어간다.
$reg[2]에는 두 번째 ()인 (c+) 에 해당하는 ccc가 들어가게 된다.
그러면 ()안에 또 ()가 들어가면 어떤 식으로 해석이 될까?
만약에 (a+(a*))a(b+(c*))라는 패턴이 있으면 어떤 식으로 들어가게 될 지를 알아보자.
먼저 $reg[0]에는 전체 패턴인 (a+(a*))a(b+(c*))에 대한 내용이 들어간다.
$reg[1]에는 첫 번째 큰 ()인 (a+(a*)) 에 대한 내용이 들어가고, $reg[2] 에는 이 괄호 안에 있는 작은 괄호 (a*) 에 대한 내용이 들어간다. $reg[3], $reg[4] 에는 각각 (b+(c*)), (c*)의 내용이 들어가게 된다.
정규 표현식을 이용하여 문자열을 치환하는 함수는 ereg_replace()와 eregi_replace() 함수가 있다.
두 함수의 차이점은 eregi_replace()의 경우에는 영문자의 대소문자 구분을 하지 않는것이다.
$str = "test test"; // 두 개의 test 사이에는 4개의 스페이스가 있다.
&str = ereg_replace(" "," ", $str);
이 명령의 실행결과로 $str = "test test"; 가 된다.
이는 내용을 출력할 때 많이 사용되는 구문이다. 그럼 문자열 치환시에 문자열 패턴을 사용할 경우 찾아낸 문자열들을 다시 사용할 방법은 어떤 것이 있는가?
이럴 때 사용되는 것들이 \\0, \\1, \\2, ... 등이다.
다음과 같은 패턴이 있다고 하자.
([_0-9a-zA-Z]+(\.[_0-9a-zA-Z]+)*)@([0-9a-zA-Z]+(\.[0-9a-zA-Z]+)*)
이런 패턴이 있을 경우 전체가 \\0이 된다.
\\1은 ([_0-9a-zA-Z]+(\.[_0-9a-zA-Z]+)*) 이 된다. \\2는 \.[_0-9a-zA-Z]+)이 된다. \\3은 ([0-9a-zA-Z]+(\.[0-9a-zA-Z]+)*) 이 되고 \\4는 (\.[0-9a-zA-Z]+)이 된다.
다음과 같은 구문이 있을 경우:
$mail = "abc@abc.net";
$pattern = "([_0-9a-zA-Z]+(\.[_0-9a-zA-Z]+)*)@([0-9a-zA-Z]+(\.[0-9a-zA-Z]+)*)";
$link = ereg_replace($pattern, "<a href = 'mailto:\\0'>\\0</a>",$mail);
결과는 <a href='mailto:abc@abc.net'>abc@abc.net</a>
이 된다.
Now here's something to make you busy:
다음의 문서들을 참고했습니다.
[1] Learning to Use Regular Expressions by Example by Dario F. Gomes
[2] 전정호님의 정규표현식 기초 ( http://www.whiterabbitpress.com/osp/unix/regex.html )
[3] 모두랑의PHP 따라잡기 게시물 ( http://modulang.net/board/view_study.php?code=class&mode=view&no=13 )
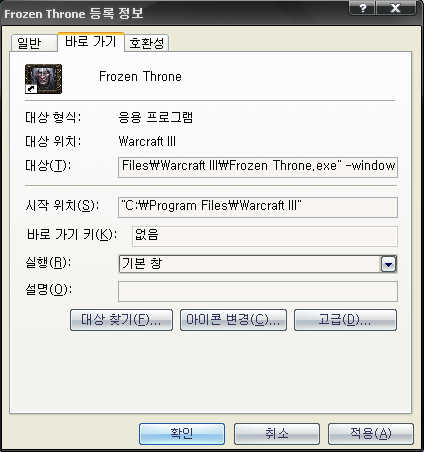
워크창모드는
워크 바로가기 아이콘을 일단 복사한다음 이름을 '창모드'로 바꾸고
아이콘에 우클릭 - 속성 - 대상 에다가
"C:\Program Files\Warcraft III\Frozen Throne.exe" -window
로 바꿔주면 끝
1. 위닝카오스를 띄우고 설정쓱쓱싹싹 해주고 적용후에 위카창을 윈도우시작버튼에 머리만 내놓게 숨겨둔다
2. 만든 워크창모드 아이콘을 따불클릭
3. 카오스 로딩이 끝나면 셀렉 "시야95" "시야고정" 다하고나서 본격적으로 캡춰마우스 프로그램을 실행
※ 창모드에서 못빠져나오겠어!! 라면
i) Alt + Tab 으로 캡춰프로그램을 선택하고 Enter (위닝카오스 단축키에 Tab이 걸려있으면 낭패;;)
ii) 윈도우키 + D 로 창을 전부 닫는다. (그리고선 인터넷서핑좀 하다가 로딩끝나면 투입)
출처 : http://www.jakartaproject.com/article/javascripttip/119862980352206
XHTML과 HTML은 현재 가장 널리 사용되는 웹 문서 규격입니다. 이름에서도 알 수 있듯이 XHTML은 기존에 사용되던 HTML 규격이 가진 문제점을 극복하고, 보다 다양한 분야에 응용될 수 있도록 해주는 여러가지 확장된 기능을 포함하고 있습니다.
HTML을 XML 바탕으로 새롭게 구성(reformulation)한 XHTML은 CSS와 함께 최근에 많은 관심을 받고 있는 ‘웹 표준’의 중요한 요소가 되었습니다. 하지만 XHTML이 XML을 기반으로 만들어졌고, 이 XML을 모든 브라우저가 지원하지 않는다는 현실적인 문제 때문에 XHTML과 HTML이 사실상 큰 차이 없이 사용된다고 주장하는 사람들도 많습니다.
이런 시각을 다루는 좋은 글이 있어서 번역해서 소개합니다. 내용이 많아서 세 번으로 나눠서 포스팅하려고 하는데 글의 전문성에 비해 제 이해가 많이 부족하고, 원문을 요약한 것이어서 그 내용을 완벽하게 전달하는데 한계가 있으니 감안해서 보시기 바랍니다.
Tommy Olsson이 쓴 원문은 Site Point 포럼에 올라온 FAQ About XHTML vs HTML이니 참고하시고, dagger 마크(†)로 시작하는 단락은 원문에는 없는 보충 설명입니다. 이 글의 저작권은 원문의 저작자인 Tommy Olsson과 Site Point에 있으며, 블로그 전체에 적용되는 CCL보다 우선적으로 적용됩니다.
첫 번째로 언급한 문법적인 차이를 다루는 문서는 많기 때문에 자세한 설명을 하지 않겠습니다.
<![CDATA[ … ]]>) 사용.<?xml-stylesheet type="text/css" href="style.css" media="screen"?>
' 캐릭터 엔티티(character entity)를 사용할 수 있다. <!-- … --> 코멘트로 스타일이나 스크립트의 일부를 주석 처리할 수 없다.
document.write() 사용).
같은 named entity를 사용할 수 없다. 미리 정의된 <, >, &, "는 사용 가능.
.innerHTML 속성을 사용할 수 없다. HTML의 일부 시작 태그는 명시적으로 지정하지 않아도 CSS가 적용된다. 예를 들어서 표(table) body 태그의 헤더 셀(header cell)에 스타일을 적용하려고 할 때 다음과 같이 CSS 규칙을 지정할 수 있다.
tbody th { text-align: left }
HTML 문서에서는 <tbody>와 </tbody> 태그를 마크업하지 않아도 이 CSS 스타일이 적용되지만 XHTML에서는 태그를 마크업하지 않으면 적용되지 않는다.
document.write() 메소드가 적용되지 않는다.
createElement() 같은 DOM 메소드는 반드시 이름 영역(namespace)에 대응되는 메소드로 바꿔줘야 한다(예: createElementNS() 사용).
.innerHTML 속성을 사용할 수 없다.
그렇지 않다. XHTML을 포함하는 XML의 문법 규칙이 HTML에 비해 더 단순하고, 일관적이지만 마크업이 유효(valid)하다면 XHTML과 HTML은 동일하게 해석(parsed)된다.
† 이 질문에서 말하는 엄격함은 문법 규칙만을 고려한 것으로 보입니다. 단순히 문법적인 면을 따져봤을 때에는 XHTML이 HTML보다 엄격한 것이 분명합니다. 하지만 원문에서 그렇지 않다고 말한 것은 브라우저가 XHTML을 HTML과 동일하게 해석하기 때문이라고 생각되네요.
그는 문단 태그(<p>)를 예로 들었는데 HTML에서는 문단을 </p> 태그로 닫지 않아도 어느 곳에서 그 태그가 닫혀야 하는지 명백하게 판단이 가능합니다. XHTML에서 </p> 태그를 생략하면 검증기(validator)는 에러를 찾아내지만 실제로 브라우저는 아무런 문제 없이 HTML과 동일한 결과를 출력하지요. 왜냐하면 거의 대부분의 XHTML 문서가 실제로는 HTML로 브라우저에게 인식되기 때문입니다. 이것은 브라우저의 XML 지원과 Content-Type에 관련된 문제인데 이 부분에 대해서는 추후에 다루겠습니다.
또한, ‘strict’라는 단어에는 ‘엄밀(정밀)하다’는 뜻도 있습니다. 이런 의미로 해석할 경우에는 HTML이 XHTML보다 정밀하다는 표현이 맞습니다. HTML을 해석하려면 생략된 태그를 판단하는 추가적인 로직이 필요하니까요. 원문에는 HTML의 문법 규칙이 XHTML보다 복잡(more complicated)하다고 표현하고 있습니다. 이 부분에 관한 자세한 내용은 원문에 달린 댓글을 참고하시기 바랍니다.
그렇지 않다. XHTML 1.0 규격은 HTML 4.01 규격을 새롭게 구성한 것이므로 두 규격은 똑같은 요소(element)와 속성(attribute)을 가지며 세 가지 문서 타입(DTD)도 동일하다. 의미론적으로는 두 규격에 아무 차이도 없다.
† 이 글을 쓰게 된 동기 중의 하나가 이 문제 때문입니다. 많은 사람들이 XHTML이 HTML보다 더 ‘의미 있는’ 규격이라고 생각하는데 실제로는 차이가 없습니다. 오히려 XHTML Transitional 규격과 HTML Strict 규격을 비교해보면 HTML Strict 규격이 ‘구조’와 ‘표현’을 훨씬 엄격하게 구분하므로 보다 의미 있는 규격입니다. 따라서 HTML Strict DTD로 작성된 문서가 XHTML Transitional 문서보다 ‘웹 표준’을 보다 잘 준수한다고 말할 수 있습니다.
그렇다. CSS를 XHTML에서만 사용할 수 있다고 생각하는 사람들이 있는데 이것은 분명히 잘못된 정보이다. 최초의 CSS 규격은 1996년에 만들어졌고, XHTML은 그 후 사 년 후에야 만들어졌다.
문서 맨 앞에 선언되는 DOCTYPE이 브라우저 같은 클라이언트 프로그램(user agent)에게 해당 문서가 XHTML이라는 것을 알려주는 역할을 한다고 생각하는 사람들이 있지만 이것 역시 사실이 아니다. DOCTYPE 선언이 만들어진 원래의 유일한 목적은 마크업을 검증하기 위한 것이며, 브라우저는 마크업을 검증할 필요가 없으므로 이 선언을 무시하고 마크업을 해석한 다음 화면에 출력했다.
하지만 매킨토시 버전의 인터넷 익스플로러 5.0(IE5/Mac)이 발표되면서 처음으로 DOCTYPE 선언을 브라우저가 이용하게 되었는데, IE5/Mac 브라우저는 구 버전이나 형제 격인 윈도우즈 버전의 브라우저보다 웹 표준을 지원하는 면에서 큰 향상을 가져왔다.
웹 표준을 보다 잘 지키면서 정확하지 않은 IE의 CSS 렌더링에 맞춰서 개발된 많은 웹 문서들에 대한 호환성을 유지하기 위해서 DOCTYPE이 사용되기 시작했다. 이 기능은 이후 인터넷 익스플로러 6.0 버전에 도입되었고, 최근에 사용되는 대부분의 브라우저에는 이 기능이 포함되어 있다.
현재 DOCTYPE 선언은 두 가지 기능을 한다. 첫 번째는 검증기(validator)가 어떤 기준으로 마크업의 유효성을 확인해야 하는지에 관한 정보를 제공하는 것이고, 두 번째는 브라우저에게 어떤 렌더링 모드를 사용할지 알려주는 기능이다. 이것은 XHTML과 HTML의 차이와는 근본적으로 아무 관련이 없다. 하지만 XHTML을 올바르게 지원하는 브라우저는 XHTML을 엄격한 표준(strict standard) 모드로 렌더링하는데 그러기 위해서는 XHTML을 올바르게 브라우저에게 인식시켜야 한다.
XHTML과 HTML의 차이에 관해서는 이것으로 마치겠습니다. 원문의 정보가 100% 옳다고 확신할 수는 없지만 100개 이상 달린 댓글을 보면 어느 정도 검증된 문서라고 판단할 수 있으리라 생각합니다.
다음 글에서는 브라우저가 왜 대부분의 XHTML 문서를 HTML과 동일하게 받아들이지는 알아보도록 하지요. 앞서 언급했던 브라우저의 XML 지원과 Content-Type에 관한 문제입니다.
from
http://blog.wystan.net/2007/05/24/xhtml-vs-html
일반적인 환경에서는 XHTML 규격에 맞게 적성된 모든 문서가 실질적으로 HTML과 동일하게 처리됩니다. 이번 글에서는 왜 그런 결과가 생기는지 그 이유를 알아보겠습니다.
이 글은 앞선 글과 마찬가지로 Tommy Olsson이 Site Point 포럼에 쓴 글을 번역한 것으로 부분적으로 dagger 마크(†)로 시작하는 보충 설명을 넣었습니다. 따라서 이 글의 저작권은 원문의 저작자인 Tommy Olsson과 Site Point에 있으며, 블로그 전체에 적용되는 CCL보다 우선적으로 적용됩니다.
웹에 있는 문서나 자원(resource)을 HTTP 프로토콜을 통해서 요청하면 웹 서버는 요청에 맞는 결과(response)를 보내주게 된다. 요청에 대한 답변은 하나 이상의 헤더와 빈 행(CR+LR), 그리고 문서의 내용(body)으로 구성되는데, HTML이나 XHTML 문서에서는 우리가 작성한 마크업이 그 내용이 된다.
HTTP 헤더는 전송할 문서에 대한 메타 정보를 제공하게 되는데, 그 중에서 가장 중요한 헤더가 Content-Type 헤더이다. 이것은 브라우저와 같은 사용자 에이전트(user agent)에게 전송할 문서가 어떤 내용을 담고 있는 문서인지 알려주는 역할을 한다. 또한 이 헤더는 문서가 어떤 문자 인코딩을 사용하는지에 관한 정보도 포함할 수 있다. 일반적인 HTML 헤더는 아래와 같이 표현된다.
Content-Type: text/html; charset=iso-8859-1
여기에서 text/html 부분을 MIME 타입이라고 부르는데 이메일 전송에서 사용되던 문서의 내용을 정의하는 규격으로 HTTP 전송에도 동일하게 적용된다.
예로 든 MIME 타입은 미디어 타입 이름(text)과 서브타입 이름(html)으로 구성되며, 문자 인코딩 정보는 생략이 가능하다.
RFC 2854 규약에 따라서 이 MIME 타입은 문서의 내용이 HTML임을 나타낸다. 그러므로 브라우저는 해당하는 문서가 마이크로소프트의 워드 문서나 GIF 이미지, 또는 XHTML 문서라 해도 무조건 HTML로 인식하고 해석한다. 다시 말해서 MIME 타입이 text/html일 경우에 그 문서는 XHTML이 아닌 HTML 문서가 된다.
XHTML이 HTML로 해석된다는 것은 XML에서만 가능한 기능들을 전혀 사용할 수 없고, 반대로 HTML에서만 가능한 기능들은 사용할 수 있다는 의미이다. 하지만 그렇게 HTML의 기능을 사용하는 것은 XHTML로 마크업한 원래의 목적에 위배되는 일이 된다.
브라우저가 XHTML을 XML 문서로 인식하고 해석하려면 아래의 세 가지 MIME 타입 중의 하나를 사용해야 한다.
W3C가 추천하는 MIME 타입은 RFC 3236 규약에 정의된 application/xhtml+xml 타입이다. 하지만 인터넷 익스플로러는 2006년 6월 현재까지 이 MIME 타입을 지원하지 않는다.
text/xml 타입도 사용할 수 있지만 기본 문자 인코딩을 처리하는 방식의 문제 때문에 추천하지 않는다. 이 타입에서는 HTTP 헤더에 인코딩 정보가 반드시 포함시켜야 하는데, 이것은 XML 선언에서 변경할 수 없다. 게다가 이 타입의 기본 인코딩은 도움이 되지 않는 US-ASCII 방식이다.
아니다. 오페라, 파이어폭스, 사파리 같은 일부 브라우저는 XHTML을 지원하지만, 가장 많은 사용자를 확보하고 있는 인터넷 익스플로러가 XHTML을 제대로 지원하지 않는다.
호환성을 위해서 W3C는 XHTML 1.0 규격에 포함시킨 HTML 호환성 가이드라인에서 text/html MIME 타입을 사용하는 방법을 제시하고 있다. 하지만 이 MIME 타입을 사용하면 모든 브라우저는 해당 문서를 HTML 문서로 인식하고 해석한다.
실질적으로 모든 브라우저가 self-closing 태그(예: <br />)의 슬래시 기호를 무시하는 해석상의 버그를 갖고 있으므로 XHTML은 HTML과 동일하게 해석된다.
† XML 문법에서는 self-closing 태그의 슬래시 기호 앞에 공백을 넣지 않아도 문법적으로 아무 문제가 없으며, <br /> 태그를 <br></br> 태그처럼 사용할 수도 있습니다. 하지만 XHTML에서는 호환성을 위해서 이런 문법을 허용하지 않습니다.
<meta/> 태그에 지정한 MIME 타입도 적용되는가?그렇지 않다. 브라우저는 HTTP 요청에 대한 답변으로 전송받는 내용(body)을 해석하기 전에 그 문서가 어떤 문서인지를 알아야 한다. 브라우저가 아래와 같은 메타 태그를 발견했을 때에는 이미 늦은것이다.
<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=utf-8"/>
MIME 타입은 반드시 HTTP 헤더로 보내야 한다. 문자 인코딩에 대한 정보는 메타 태그가 아닌 XML 선언에서 명시되어야 한다.
† Lachlan Hunt의 블로그에 실린 Content-Type에 관한 글을 참고해서 내용을 보충하자면 이렇습니다. 메타 태그의 Content-Type은 브라우저 같은 사용자 에이전트(user agent)를 위해 만들어진 것이 아니라 서버가 HTTP 헤더에 실어 보낼 Content-Type을 동적으로 변경하기 위한 목적으로 고안되었지만, 실제로는 그 역할을 못하고 있습니다. 이 메타 태그가 수행하는 유일한 역할은 W3C가 제안한 바와 같이 문서의 인코딩 정보를 알려주는 것입니다.
오페라와 파이어폭스는 로컬 문서의 확장자를 보고 어떻게 해석해야 할지 판단한다. 예를 들어서 xhtml, .xht, .xml. 확장자를 인식할 수 있다. 인터넷 익스플로러는 XHTML을 전혀 지원하지 않으므로 이런 방법이 적용되지 않는다.
서버 환경에 따라서 방법에 차이가 있지만, 아파치 서버의 경우 다음과 같은 AddType 지시문을 사용할 수 있다.
AddType application/xhtml+xml .xhtml .xht
이 지시문은 .xhtml과 .xht 확장자를 갖는 문서를 application/xhtml+xml MIME 타입으로 전송하도록 서버에 지시한다. 이 명령은 아파치 서버의 전역 설정(/etc/httpd.conf)이나 웹 디렉토리의 .htaccess 파일에 적용된다.
이런 설정 파일에 접근할 수 없는 경우에는 서버-사이드 스크립트 언어를 사용해서 같은 결과를 얻을 수 있다. 예를 들어서 PHP 언어를 사용한 다음 코드를 이용할 수 있다.
header('Content-Type: application/xhtml+xml; charset=utf-8');
이 헤더가 문서의 내용이 전송되기 전에 브라우저에게 전해져야 한다는 것을 명심하라.
application/xhtml+xml 타입으로 전송하면 어떤 장점이 있는가?말 그대로 브라우저가 XHTML을 XHTML로 인식한다. XHTML을 사용할 경우에만 얻을 수 있는 장점 때문에 XHTML 문서를 작성했다면 그 장점을 그대로 누릴 수 있다.
Content Negotiation은 하나의 HTTP 요청에 대해서 두 가지 이상의 자원(문서, 이미지 등)을 준비해서 사용자 에이전트(user agent)에 따라 선택적으로 제공하는 방법이다. 예를 들어서 application/xtml+xml을 지원하는 오페라, 파이어폭스, 사파리 브라우저는 XHTML 문서를 application/xtml+xml 형태로 제공하고 인터넷 익스플로러가 요청할 때에는 HTML 마크업으로 작성된 HTML 문서를 text/html 형태로 보낼 수 있다.
하지만 이런 방법으로 얻을 수 있는 이점은 다른 컴퓨터 광(geeks)들에게 자신의 능력을 보여주는 것 외에는 전혀 없다. HTML로 변환시킬 수 있는 문서라면 XML만이 지원하는 기능을 전혀 사용하지 않았을 것이기 때문이다. 그렇다면 이름만 다른 두 개의 문서(XHTML, HTML)를 준비하는 것보다 HTML 4.01 스팩을 따르거나 XHTML을 text/html로 제공하는 것이 훨씬 쉬운 방법이다.
Content Type Negotiation은 더 의미가 없다. 같은 문서를 브라우저에 따라 서로 다른 Content-Type으로 보내서 얻을 수 있는 이점은 전혀 없다.
† Content Negotiation을 쉽게 이해하려면 GIF 이미지와 PNG 이미지를 생각하면 됩니다. 동일한 두 가지 이미지를 준비해서 PNG를 제대로 지원하지 않는 인터넷 익스플로러 6.0에게만 GIF 이미지를 전송하는 방법이지요. 자세한 설명은 Content Negotiation에 관한 위키피디아 문서를 참고하세요.
Content Type Negotiation은 모든 요청에 대해 동일한 내용(content)을 전송하면서 HTTP 헤더 정보만 달리하는 것을 말합니다. 동일한 문서가 XHTML도 되고, HTML도 되는 방식입니다.
불가능하다. 익스플로러가 application/xhtml+xml MIME 타입을 지원하지 않으므로 이런 헤더 정보를 받게 되면 해당 페이지를 다운로드하려고 한다. 레지스트리를 변경해서(hack) 이 MIME 타입을 인식하도록 할 수는 있지만 그렇다고 해도 해당 문서는 여전히 HTML로 취급된다.
XHTML의 XML 기능이 필요하다면 문서를 application/xml로 제공할 수 있다. 인터넷 익스플로러도 이 MIME 타입을 지원하지만 XHTML의 이름 영역(namespace)를 사용할 수 없으므로 해당 문서는 보통의 XML 문서로 인식된다. 따라서 스타일시트가 기본적으로 적용되지 않으므로, 모든 요소에 대한 스타일을 전부 지정해줘야 한다. 예를 들어서 모든 블록 레벨의 요소들에 display: block 속성을 지정해야 한다.
물론 XHTML을 text/html로 제공할 수 있다. 하지만 앞서 길게 설명했던 것처럼 브라우저는 그 XHTML 문서를 문법 오류가 있는 HTML 문서로 인식한다.
† 여기서 말하는 문법 오류는 닫는 태그 앞에 공백과 슬래시 기호가 있는 것을 의미합니다. 예를 들어서 <br /> 태그 같은 것이지요.
그렇지 않다.
마지막 질문에 대한 짧은 답이 인상적입니다.
간단하게 요약하자면 브라우저가 XHTML을 제대로 지원하지 않고, XHTML과 HTML의 기능이 완벽하게 호환되지 않으므로 대부분의 XHTML 문서는 HTML과의 하위 호환성을 고려해서 작성된다는 얘기입니다. 그렇게 작성된 문서에 XML을 지원하는 브라우저에서만 해석 가능한 마크업이 들어갈 리 없으니 겉모습은 XHTML이라도 실제로는 HTML과 다를 바 없다는 것이 원문의 주장입니다.
다음 글에서는 그럼에도 불구하고 XHTML이 널리 사용되는 이유와 마지막으로 발표된 W3C의 XHTML 규격인 XHTML 1.1에 대해서 알아보도록 하겠습니다.
마지막으로 사용자가 자신의 웹 페이지를 요청했을 때 서버가 어떻게 답하는지 궁금한 분들은 W3C의 HTTP Head 서비스를 이용해 보시기 바랍니다. 제 블로그를 확인해 보니 아래 결과가 나오더군요.
200 OK
X-Powered-By: PHP/4.4.2AnNyung
Server: Apache -OOPS Development Organization-
Connection: close
Date: Thu, 24 May 2007 11:56:37 GMT
P3p: CP='CAO PSA CONi OTR OUR DEM ONL'
Content-Type: text/html; charset=utf-8
마지막 줄에 있는 Content-Type: text/html; charset=utf-8은 제가 이용하고 있는 비누넷 호스팅 서버의 기본 설정입니다. XHTML 문서의 메타 태그로는 바꿀 수 없다는 것에 주의하세요.
from
http://blog.wystan.net/2007/05/24/xhtml-mime-type
W3C가 2001년 5월에 발표한 최종 XHTML 권고안이 XHTML 1.1 규격입니다. 하지만 XHTML을 소개하는 문서들의 대부분은 2000년 1월에 발표된 XHTML 1.0 규격에 관한 정보를 담고 있고, 현재 사용되는 XHTML 웹 문서들도 대부분 XHTML 1.0 규격을 따르고 있습니다.
그렇다면 최신 규격이라고 말할 수 있는 XHTML 1.1이 XHTML 1.0 규격에 비해 상대적으로 훨씬 덜 알려지고 덜 사용되는 이유는 무엇일까요? 해답을 찾기 위해서 먼저 두 규격의 차이점을 알아보겠습니다.
이 글은 앞서 작성한 글과는 달리 Tommy Olsson이 Site Point 포럼에 올린 글의 일부만을 인용해서 설명하도록 하겠습니다. 원문에는 XHTML 1.1 규격에 관한 부분이 상당히 간략하게 설명되어 있거든요.
크게 두 가지 차이점이 있습니다. 첫 번째는 기존의 XHTML 1.0 규격에 모듈화를 도입했다는 것이고, 두 번째는 루비 주석(Ruby annotation)을 지원하기 위한 태그가 있다는 것이지요.
사실 XHTML 1.1은 실질적으로 기존의 XHTML 1.0, 그중에서도 XHTML 1.0 Strict 규격과 큰 차이가 없습니다. 왜냐하면 이 규격을 기반으로 모듈화를 도입했기 때문이지요. 그래서 XHTML 1.0 Strict 규격에 맞게 작성된 페이지는 DOCTYPE만 1.1로 바꿔주면 거의 대부분 아무 문제없이 마크업 검증기(validator)를 통과합니다. 문법적으로 달라진 차이점은 정확하게 세 가지입니다.
lang 속성이 사라지고, 대신 xml:lang 속성이 도입되었다.
a와 map 요소에 적용되던 name 속성 대신 id 속성을 사용해야 한다.
XHTML 1.1에 도입된 모듈화는 기존에 평등한 관계에 있던 태그 요소(element)들을 수행하는 기능에 따라 몇 개의 분류로 나눈 것입니다. 이렇게 나뉘어진 모듈들을 조합해서 XHTML 문서를 작성할 수 있고, 사용자에게 필요한 추가적인 모듈을 사용해서 문서의 기능을 확장할 수 있도록 한 것이지요.
W3C는 모듈화로 얻을 수 있는 이점을 다음과 같이 밝히고 있습니다.
“단순히 웹 문서에만 사용되던 HTML이 다양한 분야와 기기(모바일 기기, 디지탈 TV 등)에 점점 더 많이 적용되고 있는데 이들 각각은 서로 요구하는 조건이나 구현상의 한계가 다르므로 기존의 규격을 일괄적으로 적용시키기가 어렵다.”
“이런 문제를 해결하기 위해 도입된 모듈화를 통해서 서비스나 기기를 디자인할 때 표준에 맞게 만들어진 블록을 사용하고, 표준에 맞는 방법으로 어떤 블럭을 사용했는지 알려주는 방식으로 해당 기기가 어떤 모듈을 지원하는지 컨텐츠 커뮤니티(content community)에 명확하게 알려줄 수 있다. 그러면 컨텐츠 커뮤니티는 필요한 특정 모듈을 지원하는 이미 만들어진 기반(installed base)에만 신경을 써서 컨텐츠를 만들어낼 수 있다.”
“표준화된 방식을 사용함으로써 소프트웨어는 기기에 맞게 컨텐츠를 처리할 수 있고, 기기는 필요한 모듈을 처리하기 위한 소프트웨어를 자동으로 불러올(load) 수 있게 된다.”
“또한, 모듈화와 XML의 확장성을 이용해서 XHTML 표준을 어기지 않고도 XHTML 문서의 레이아웃과 디자인의 확장성을 높일 수 있다.”
† 원문을 의역하고 요약하는 과정에서 원래 의미를 잘못 전달할 수 있습니다. 언제나 오역을 염두에 두시고 봐주세요. ^^;
루비는 특정한 텍스트와 관련 있는 다른 텍스트를 함께 표기하는 방법을 의미하며 중국어나 일본어 표기에 사용됩니다(프로그래밍 언어 ‘루비’와는 아무 관련 없음). XHTML 1.1 규격에는 루비 표기를 지원하는 모듈이 포함되어 있는데, W3C가 모듈화의 예를 들기 위해서 넣지 않았나 하는 생각이 드네요. 루비가 어떻게 사용되는지 알려드리기 위해서 W3C의 루비 주석 규격에서 가져온 이미지를 보여드리겠습니다.
![]()
설명하지 않아도 어떻게 사용되는지 아시겠지요? 다른 예를 이미지와 XHTML 1.1 코드로 알아보겠습니다.
![]()
<ruby>
<rb>WWW</rb>
<rt>World Wide Web</rt>
</ruby>
루비 주석에 관한 자세한 설명은 생략하겠습니다. ^^
일단 인터넷 익스플러러는 XHTML을 제대로 지원하지 않습니다. 앞선 글에서 Content-Type에 관해 설명했듯이 XHTML의 XML 기능을 사용하기 위한 필수 요구 조건인 application/xhtml+xml MIME 타입을 인식하지 못하지요.
인터넷 익스플로러를 제외한 일부 브라우저, 예를 들어서 파이어폭스는 XHTML을 지원합니다. 하지만 그렇다고 해서 위에서 설명한 루비 주석을 작성하기 위한 마크업을 인식할 수 있을까요?
현재까지는 그렇지 않습니다. 파이어폭스에서 위에서 예로 들었던 루비 주석 마크업의 결과물을 보려면 플러그인을 따로 설치해야 합니다.
† 인터넷 익스플러로 5.0 이후의 브라우저는 제한적으로 루비 주석 표기를 지원합니다. 하지만 인터넷 익스플로러 5.0이 1999년에 발표되었다는 사실에서 짐작할 수 있듯이 W3C가 XHTML 1.1 규격에서 제안한 방식으로 구현된 것은 아닙니다. 비 표준적인 태그 지원이라는 얘기지요. 그러므로 XHTML이 아닌 HTML에서도 루비 주석을 표현할 수 있으며 XHTML의 MIME 타입과도 무관합니다.
이 중요한 문제의 답으로 Tommy Olsson의 글을 인용하겠습니다.
“XHTML 문서를
text/htmlMIME 타입으로 제공할 때에는 절대로 XHTML 1.1 규격을 사용하지 말아야 한다. 왜냐하면 XHTML 1.1에서lang속성이 금지(deprecate)되었기 때문에 HTML과의 하위 호환성을 유지할 수 없기 때문이다.”
XHTML 1.0에서는 HTML과의 호환성을 위해서 해당 문서가 어떤 언어로 작성되었는지 lang 속성과 xml:lang 속성 두 가지를 모두 지정할 것을 권장합니다. XHTML을 지원하는 브라우저는 xml:lang 속성을 이해할 수 있고, 그렇지 않은 브라우저는 lang 속성을 이해할 수 있으니까요.
하지만 XHTML 1.1을 text/html MIME 타입으로 제공하면 브라우저가 해당 문서를 HTML로 취급하게 됩니다. 당연히 xml:lang 속성을 해석할 수 없겠지요. 그 문서가 어떤 언어로 작성되었는지 알려줄 방법이 없다는 얘기입니다.
물론 사용한 언어를 지정하지 않아도 대부분의 브라우저는 지금 보시는 이 페이지 처럼 알아서 문서를 해석합니다. ^^; W3C의 XML 규격에는 이렇게 나와있네요.
“XML 문서를 처리할 때 문서가 어떤 언어로 작성되었는지 아는 것이 유용할 때가 많다(often useful). 어떤 언어로 작성되었는지 알려주기 위해서
xml:lang속성을 사용할(may) 수 있다.”
하지만 DTD 선언을 한 상태에서 xml:lang 속성을 지정하지 않으면 XML 검증기(validator)가 마크업이 유효하지 않다고 불평한다고 하네요. 결국 선언해야 한다는 얘기지요.
또한, 당장 브라우저가 아무 문제없이 문서를 해석한다고 해도 다른 기기에서 문제를 일으킬 가능성이 있으므로 Tommy Olsson의 주장이 옳다고 생각합니다.
역시 Tommy Olsson의 글을 인용하겠습니다.
“루비 주석을 표기할 필요가 있고, 그 문서를 이용하는 사용자가 루비 주석에 관한 마크업을 해석할 수 있는 플러그인을 설치했을 경우가 아니라면 XHTML 1.1을 사용해서 얻을 수 있는 것은 아무 것도 없다.”
한 마디로 불필요하다는 얘기지요. 사용자가 가장 많은 인터넷 익스플로러는 XHTML을 아예 지원하지 않고, 그나마 지원하는 브라우저에서도 XHTML 1.1의 새로운 기능인 루비 주석을 표현하려면 플러그인을 설치해야 합니다. 게다가 HTML과의 하위 호환성도 보장할 수 없으니 그렇게 주장하는 것이 당연하지 않을까요?
대부분의 XHTML 문서가 왜 최신 규격이 아닌 XHTML 1.0 규격을 따르는지 알아봤습니다. 원래는 이번 글을 끝으로 XHTML과 HTML의 차이에 관한 글을 마치려고 했는데 아직 설명해야 할 것들이 남아있네요. 다음 글에서는 여러가지 문제점에도 불구하고 많은 사람들이 XHTML에 관심을 갖고 사용하려는 이유에 대해서 알아보겠습니다.
from
http://blog.wystan.net/2007/05/26/xhtml11-usage-and-compatibility
XHTML이 어떤 마크업 언어이고, 어떤 한계를 가지고 있는지를 앞선 글에서 알아봤습니다. 그렇다면 HTML 대신 XHTML을 사용하는 것은 과연 옳은 선택일까요? 이 주제에 관해서 포스팅하게 된 동기가 되었던 Tommy Olsson의 글에서는 이 문제에 대해서 부정적인 입장을 취하고 있습니다. XHTML이 실제로는 HTML과 거의 동일하게 취급되므로 구태여 XHTML을 사용할 필요가 없다는 주장이지요.
하지만 XHTML을 이용한 홈페이지와 블로그를 만들고 운영하는 제 생각은 그와는 다릅니다. XHTML이 HTML 대신 사용되는 것을 굳이 말릴 필요는 없다고 생각하거든요.
물론 이 문제에는 정답이 없습니다. 각자가 생각하고 판단해야 할 문제니까요. 그 판단을 돕기 위해서 각각의 주장에 대해서 자세히 설명하려는 것이 이 글의 목적입니다.
그리고 이 글은 XHTML 1.0과 HTML 4.01 규격을 비교하는데 중점을 두겠습니다. 하위 호환성을 보장할 수 없는 XHTML 1.1 규격을 특별한 목적 없이 사용해서 얻을 수 있는 것은 최신 규격을 지켰다는 심리적 만족 외에는 없다고 생각하므로 이 규격에 대해서는 언급하지 않겠습니다. 많은 사람들이 W3C의 권고안, 즉 표준을 완전무결한 기준으로 받아들이는데 그런 생각은 W3C의 권위가 불러오는 함정이 될 수 있습니다.
먼저 Tommy Olsson의 글을 일부 인용하겠습니다.
“XHTML과 HTML 중에서 어느 것을 선택해야 하는지에 관한 절대적 기준은 없으며, 이 문제에 관한 여러가지 기술적인 문제들을 생각했을때 간단히 답할 수 있는 문제가 아니다. 하지만 현실적으로 가장 호환성이 높은 W3C의 마지막 표준은 HTML 4.01이라 말할 수 있다. 당신이 실제로 HTML로는 불가능한 XHTML의 기능을 사용해야 하는 경우를 제외하면 기술적인 면에서 XHTML을 사용해야 할 이유는 전혀 없다.”
“XHTML을 사용해서 실익을 얻으려면 XHTML과 HTML의 근본적인 차이점을 이해해야 한다. 하지만 XHTML을 제대로 사용하는 사이트를 이용할 수 있는 것은 전체 웹 사용자들의 일부일 뿐이다.”
“일부 웹 디자이너와 개발자들은 XHTML의 문법 규칙을 선호한다. 특정한 지침을 따른다면, XHTML의 기술적인 면을 전혀 사용하지 않고서도 XHTML의 문법을 사용할 수 있다. 이런 접근 방식에는 잠재적인 문제점이 있지만,
<br>태그 대신 반드시<br />태그를 사용하기를 원한다면 그 방식을 따르면 된다.”“당신의 문서가 미래의 환경에서도 유효하려면(future-proofing) XHTML과 HTML에서 어느 것을 선택하느냐 보다 Transitional 대신 Strict DOCTYPE을 사용하는 것이 훨씬 중요하다.”
그의 주장의 바탕이 되는 이유는 앞선 글에서 설명했던 브라우저의 XHTML 호환성 문제 때문인데 이에 관한 설명은 브라우저가 XHTML을 해석하는 방식을 참고하시기 바랍니다.
마지막 문장에 대해서는 XHTML과 HTML의 차이에서 이미 다루었지만, 중요한 의미가 있어서 다시 한번 짚고 넘어가겠습니다.
많은 사람들이 XHTML을 사용하면 문서의 ‘구조’와 ‘표현’을 HTML보다 잘 분리해서 보다 ‘의미 있는’ 마크업을 할 수 있다고 생각하지만 이것은 사실이 아닙니다. 이런 면에서 두 규격은 서로 대등하니까요. 동일한 Strict DTD로 정의된 XHTML 1.0과 HTML 4.01 문서는 사용할 수 있는 요소(element)와 속성(attribute)에 차이가 거의 없습니다. 단지 <br> 태그 대신 <br /> 태그를 사용하는 것처럼 문법 규칙이 다를 뿐이지요.
CSS를 사용하는 것도 마찬가지입니다. XHTML과 HTML 모두 동일하게 적용되지요. 그러므로 XHTML로 가능한 문서의 ‘구조’와 ‘표현’의 분리는 HTML로도 똑같이 할 수 있습니다.
하지만 점점 더 많은 사람들이 HTML대신 XHTML을 사용해야 한다고 주장합니다. Tommy Olsson은 그 이유를 다음과 같이 밝히고 있지요.
“많은 웹 디자이너와 개발자들이 XHTML 1.0의 발표에 환호했다. XHTML은 당시에 크게 유행했던 XML이었고 HTML처럼 쉽게 사용할 수 있었으며 모든 브라우저에서 잘 동작했다. 사람들은 XHTML의 확장성에서 많은 가능성을 발견했고, W3C가 더 이상의 HTML 규격은 아마도 없을 것이라고 발표하면서 XHTML이 미래 환경을 위한 유일한 대안이라고 생각하게 되었다.”
“시간이 흐르면서 XHTML 사용의 문제점과 확장성의 한계가 밝혀졌지만 XHTML에 대한 장밋빛 환상만큼 널리 알려지지는 않았다. 이 사실을 알지 못하거나 개인적인 선호 때문에 많은 사람들은 여전히 HTML보다는 XHTML을 사용해야 한다고 주장하고 있다.”
여기서 말하는 XHTML은 XML의 기능이 사용되지 않아서 HTML로도 충분히 처리가 가능한 마크업을 말합니다. XML의 기능이 꼭 필요하다면 당연히 XHTML을 사용해야겠지요. 하지만 이 글을 읽으시는 분들 중에서 XML을 사용했기 때문에 인터넷 익스플로러로는 접근할 수 없는 그런 페이지를 단 한번이라도 보신 적이 있는지요?
† 인용한 문장에서는 HTML 4.01이 W3C의 마지막 HTML 표준이 될 것이라 생각하는데, 이것은 Tommy Olsson의 원문이 2006년 6월에 씌여졌기 때문입니다. 현재 W3C에서는 HTML 5와 XHTML 5를 위한 워킹 그룹이 새로운 표준의 밑그림을 그리고 있습니다. HTML 5는 애플, 모질라, 오페라 진영의 사람들이 모여서 설립한 WHATWG에서 자신들이 개발중인 규격을 W3C의 새로운 HTML 규격을 위한 초안으로 채택해줄 것을 제안했고, W3C가 이 제안을 받아들이면서 세상에 그 이름을 알리게 되었습니다(2007년 5월). 현재 이 워킹 그룹의 편집 책임자는 구글의 Ian Hickson과 애플의 David Hyatt입니다.
Tommy Olsson은 XHTML이 HTML과 다를 바 없으므로 HTML을 사용하는 것이 더 나은 선택이라고 주장합니다. 하지만 역설적으로 그렇기 때문에 XHTML을 사용하는 것이 아닐까요? 다시 말해서 HTML 대신 XHTML을 사용해서 얻을 수 있는 이점은 없지만, 그렇다고 해서 특별히 단점이 있는 것도 아니니까요.
XHTML을 HTML처럼 사용하는 것이 잠재적인 문제점(potential pitfall)을 안고 있다고 하지만 그것은 어디까지나 브라우저 같은 사용자 에이전트(user agent)의 내부적인 처리 방식의 문제입니다. 결과적으로 XHTML은 HTML과의 호환성을 유지하고, XHTML 문법 규칙은 혼란을 일으키지 않을 만큼 충분히 명확하기 때문에 사용자에게는 아무런 문제가 되지 않습니다.
또한 XHTML을 사용하면 HTML보다 양식화된(well-formed) 문서를 작성할 수 있는데 이것은 브라우저가 아닌 사용자 입장에서 특히 유익합니다. 브라우저는 </p> 태그가 없어도 문단이 어디서 끝나는지 명확하게 알 수 있지만, 사용자는 그것을 알기가 어려우니까요.
물론 HTML을 사용해도 동일하게 양식화(well-formed)된 문서를 작성할 수 있습니다. </p> 태그는 생략할 수 있는 것이지 생략해야 하는 것이 아니기 때문입니다. 하지만 XHTML을 사용하면 마크업 검증기(validator)가 문서의 양식을 더 꼼꼼하게 확인합니다. 따라서 XHTML 마크업을 작성하고 검증해보는 것이 양식화된 마크업을 익히는데 유리합니다.
미래의 웹 환경이 어떻게 달라질지 예상하는 것은 어렵습니다. 하지만 단시일 내에 모든 브라우저들이 완벽하게 XML을 지원하리라고는 믿지 않습니다. 개인적으로는 XHTML 문서를 나타내는 .xhtml 확장자가 지금의 .html 확장자 만큼 익숙해져야 XHTML 문서가 그 힘을 발휘할 수 있다고 생각하는데 그 때를 대비해서 XHTML을 써야한다고 주장하는 것이 아닙니다. 앞서 말씀드렸듯이 지금 작성되는 대부분의 XHTML 문서에는 XML 만의 기능이 들어가 있지 않으니까요. XHTML의 하위 호환성을 고려했을 때 HTML 대신 사용해도 무방하다는 것이 제 의견의 요지입니다.
XHTML과 HTML 규격의 차이점을 다루는 글을 쓰게 된 동기는 ‘웹 표준’과 XHTML 사용을 동일하게 받아들이는 일부의 시각 때문입니다. HTML 4.01 규격도 엄연히 W3C가 제정한 표준 권고안임에도 불구하고 XHTML과 CSS를 사용해야만 웹 표준을 지킬 수 있고, 그것이 무조건 더 좋은 방법이라고 생각하는 분들이 있는데 절대적으로 틀린 생각입니다.
웹 표준을 잘 지키고 그 장점을 누리기 위해서는 XHTML과 HTML의 차이가 아니라 Strict와 Transitional DTD의 차이를 아는 것이 훨씬 더 중요합니다. 이 주제에 관해서는 나중에 다루도록 하고, XHTML과 HTML 규격의 차이점에 관한 글은 이것으로 모두 마칩니다.
from
출처 : http://kwon37xi.egloos.com/2793511
|
Java 웹 어플리케이션을 개발하다보면, 의외로 자기가 현재 사용중인 JSP/Servlet 스펙의 버전을 모르는 상태로 개발하는 것을 많이 보게 된다. 특히, 자주 나타나는 것으로 개발은 Tomcat 에서 하면서, 실제 갑은 톰캣이 아닌 다른 WAS를 사용할 경우가 있는데, 이는 나중에 아주 심각한 문제로 대두될 수 있다. Tomcat 5에서 Tomcat 5가 지원하는 JSP 2.0/Servlet 2.4로 (해당 스펙의 기능을 이용해서) 개발했다가, 나중에 갑이 우리는 죽었다 깨나도 웹 로직 8.1(JSP 1.2/Servlet 2.3) 쓸래... 그래버리면, 그때부터는 열심히 노가다로 고쳐야 된다. 간단하게 JSP/Servlet 스펙을 내가 아는대로 정리해본다. 특히 개발시 Tomcat으로 개발 환경을 구축한다면, 갑이 원하는 WAS가 지원하는 스펙 버전을 확인해서 그 스펙 버전에 맞는 톰캣을 사용하도록 한다. 물론 각 WAS별 지원 스펙은 해당 WAS의 업체에 물어보면 된다. Tomcat 버전별 지원 스펙 * Tomcat 3.x : JSP 1.1, Servlet 2.2 * Tomcat 4.x : JSP 1.2, Servlet 2.3 * Tomcat 5.x : JSP 2.0, Servlet 2.4 위 내용은 http://tomcat.apache.org/whichversion.html에서 확인할 수 있다. 물론 상위 버전을 지원하는 WAS는 하위 버전 스펙도 지원한다. Tomcat 5.x에서 JSP 1.1/Servlet 2.2 어플리케이션 짜도 괜찮다. 하지만 안그러는게 더 안전할 거 같다. Tomcat 3.x : JSP 1.1, Servlet 2.2 는... * web.xml 에서 다음과 같은 DTD를 선언해줘야 한다. <?xml version="1.0" encoding="ISO-8859-1"?> * 한글 파라미터 처리에 심각한 문제가 있다. ServletRequest.setCharacterEncoding(String)메소드가 존재하지 않기 때문에 각 요청에 대해 일괄적인 문자 인코딩 지정을 할 수가 없다. * 한글 파라미터 처리를 하려면 모든 요청에 대해서 다음 처럼 인코딩 변환작업을 해줘야 한다. String param = new String(request.getParameter("param").getBytes("latin1"),"euc-kr"); 위와 같은 노가다를 안 하려면 MVC 패턴 프레임워크를 사용하면서 Controller 부분에서 일괄적으로 request 객체를 바꿔치기해서 getParameter()가 인코딩을 자동으로 해주도록 해야 한다. Spring MVC에서 그런식으로 한 예제(이거도 사실 불완전함). 사실.. 한글 문제가 아니더라도 MVC패턴 프레임웍을 쓰는것이 여러모로 좋은 것은 이미 다들 아실거 같다. * Filter와 Listener가 존재하지 않는다. 특히 Filter는 상당한 노가다를 줄여주는 역할을 해서, 많이 애용되지만 JSP 1.1/Servlet 2.2에는 존재하지 않는다. * 서블릿을 web.xml에서 매핑하지 않고 패키지명을 포함한 클래스의 완전한 이름을 통해 브라우저에서 서블릿의 직접 호출이 가능하다. 매우 좋지 않은 습관이지만 어쨌든 가능하다. 너무 오래된 스펙이고 불편한 점이 많으므로 되도록 사용하지 않는게 좋다. 갑이 이 스펙의 WAS를 요구하면 설득해서 최소한 JSP 1.2/Servlet 2.3 으로 바꾸도록 하길 권장하고 싶다. Tomcat 4.x : JSP 1.2, Servlet 2.3 는... * web.xml 에서 다음과 같은 DTD를 선언해줘야 한다. <?xml version="1.0" encoding="ISO-8859-1"?> * ServletRequest.setCharacterEncoding(String)를 통해서 파라미터의 문자 인코딩을 일괄적으로 지정할 수 있다. * Filter와 Listener가 존재한다. * Filter와 ServletRequest.setCharacterEncoding(String)를 이용하면, 한번에 한글 관련 설정이 끝난다. FIlter 강좌 하나...(영문) Listener 강좌 하나...(영문) : 리스너는 웹 어플리케이션이 시작/종료 되거나, 세션 생성/파괴와 같은 특정 이벤트가 발생할 때 부가적인 작업을 해줄 수 있도록 하는 클래스이다. * 기본적으로 서블릿 매핑을 web.xml에 작성하지 않으면 서블릿을 호출할 수 없다.(이게 더 좋은거다... 보안상) * JSTL 1.0 이 도입되었다. JSP 1.2/Servlet 2.3 이 현재 우리나라에서 제일 많이 쓰이는 것으로 보이며 개발시 어느정도 무난하다 할 수 있다. Tomcat 5.x : JSP 2.0, Servlet 2.4 는... * web.xml 에서 다음과 같은 Schema를 선언해줘야 한다. <?xml version="1.0" encoding="ISO-8859-1"?> * 쉽고 강력해진 Tag Library 작성기능. * EL을 JSTL이 아닌 모든 템플릿 문자열에서 사용가능하다. * JSTL 1.1 이 도입되었다. * Function 커스텀 태그를 만들 수 있다. * 그외 자세한 JSP 2.0/Servlet 2.4의 변경 사항 JSP 2.0 뭐가 바뀌었나를 참조한다. Tomcat 4.x/5.x에서의 한글 문제 해결법도 한 번 읽어보시길 권한다. 개인적으로는 JSP 2.0/Servlet 2.4의 사용을 권장하고 싶다. 스펙 버전이 올라갈 수록 JSP 개발은 더 쉬워지고 생산성도 높아진다(물론 갑이 이 스펙을 지원하는 WAS 사용을 결정했을 때 얘기이다). |
규칙1: properties 파일은 Text 파일이며, 다음과 같은 형태의 이름들을 가질 수 있습니다.
MyResource_ko_KR_IBMeucKR.properties
MyResource_ko_KR.properties
MyResource_ko.properties
MyResource_en_US.properties
MyResource_en.properties
MyResource.properties
baseclass "_" language1 "_" country1 "_" variant1
baseclass "_" language1 "_" country1
baseclass "_" language1
baseclass
즉, 자동으로 JVM의 Locale 정보를 찾아서 위 순서대로 프로퍼티 파일을 순차적으로 찾아
나갑니다.
Locale 옵션을 주지 않으면, Locale.getDefault()를 사용하게 됩니다.
System.out.println(Locale.getDefault()) 해 보시면 확인이 가능하며, 이 값은
"file.encoding" 이라는 System Property 값에 의해 영향을 받으며, 이것은 다시
환경변수 "LANG" 값에 영향을 받습니다.
이 기능을 이용하여, Locale 값이 무엇이냐에 따라 서로 다른 문자열을 프로그램내에서
제공할 수 있게 되는 것이지요...
즉, 아래와 같은 서로 다른 이름의 resource 파일을 두게 되면, 영어와 한글 문자열을
Locale 값에 따라 서로 다르게 제공할 수 있는 것이지요.
MyResource_ko.properties
MyResource_en.properties
MyResource.properties <--- 이도저도 아닐 때 사용되는 defualt
규칙2: 위의 해당 properties 파일은 classpath 에 잡혀 있는 곳에 있어야 하며,
만약, package 로 구분된 sub directory 에 두었다면, 반드시 full path 를 주어야
합니다.
ResourceBundle resource =
ResourceBundle.getBundle("org.jsn.somewhere.MyResource")
그리고, MyResource_??_??.properties 파일들(!)은 org/jsn/somewhere/ 하부 디렉토리에
놓여 있어야 합니다.
해당 properties 파일들은 jar 파일내에 함께 묶어 두어도 됩니다.
규칙3: properties 파일들은 다음과 같은 포멧으로 구성되어 있습니다.
----------------------------------------------------------------------
# 1. key = value_string 으로 기술된다.
# 2. Comment 는 '#'으로 시작되면 되나, 문자열 중간에 있는 '#'기호는 Comment로
# 인식하지 않는다.
# 3. '=' 대신 ' '(공백)을 사용해도 된다.
# (즉 첫번째 나오는 공백이 key와 vlaue string를 나누는 구실도 한다.
# 4. 3번의 이유로 인하여 key에는 중간에 공백이 허용되지 않는다.
# 5. 반면, value string에는 공백이 허용된다.
# 6. value string를 사용할 때 한글이 지원된다. 그러나 key는 한글지원이 안된다.
# 7. 두 줄 이상을 사용하려면 라인의 끝에 '\' 문자를 사용하면 된다.
# '\'문자 자체가 필요할 땐 '\' 대신 '\\'을 사용하라.
# 8. 7번의 이유로 인하여 Windows 환경에서 디렉토리 구분은 '\'가 아니라 '\\' 이다.
key = value
name = 이원영
.....
----------------------------------------------------------------------
규칙4: 한글은 8859_1 캐릭터 셋으로만 읽혀 집니다. 따라서, JVM의 인코딩이 8859_1 이
아니라면, 다음처럼 변환하여야 합니다. file.encoding 이 "KSC5601" 이라면,
ResourceBundle resource = ResourceBundle.getBundle("resource.MyResource");
System.out.println(Locale.getDefault());
System.out.println(resource.getString("name"));
System.out.println(new String(resource.getString("name").getBytes("8859_1"),"KSC5601"));
내부적으로 ClassLoader.getResourceAsStream(filename); 의 형태로 읽혀 들이기
때문입니다.
보다 자세한 사항은 해당 클래스의 API 문서와 JDK 소스를 직접 읽어 보시길 바랍니다.
가장 빨리/정확히/깊이있게 공부하는 지름길입니다.
-------------------------------------------------------
본 문서는 자유롭게 배포/복사 할 수 있으나 반드시
이 문서의 저자에 대한 언급을 삭제하시면 안됩니다
================================================
자바서비스넷 이원영
E-mail: javaservice@hanmail.net
PCS:011-898-7904
================================================
출처 : http://www.javaservice.net/~java/bbs/read.cgi?m=devtip&b=javatip&c=r_p&n=993541416&p=13&s=t
 invalid-file
invalid-file